25.11.2025 aktualisiert

Premiumkunde
nicht verfügbarDatabricks Data Engineer|Data Cloud Architect|RAG Data Scientist|Azure,AWS,Snowflake certified
Offenbach am Main, Deutschland
Weltweit
Master Wirtschaftsinformatik (M.Sc.)Skills
JavaJavascriptAPIsAgile MethodologieAirflowIBM AixAmazon Web ServicesAmazon S3Application ServiceArchitekturComputer VisionTest AutomationMicrosoft AzureBash ShellBig DataUNIXCloud ComputingIt-BeratungDatenbankenContinuous IntegrationInformation EngineeringDateiData IntegrationETLData MigrationData MiningDatenmodellData VaultData WarehousingIBM DB2LinuxGreenplumFailoverR (Programmiersprache)Apache HadoopHadoop Distributed File SystemApache HiveJsonPythonKinesiologiePostgresqlMachine LearningProjektmanagementMicrosoft Sql-ServerMysqlNatural Language ProcessingOperational Data StoreOracle FinancialsWindows PowershellProdukt ManagementScrumQualitätsmanagementPower BiCloud-ServicesSeleniumSoftwareentwicklungVaultPL/SQLSQLStatistikenTableauTransact-SqlAnforderungsspezifikationenUser StoriesExtensible Markup LanguageParquetAblaufplanungDatenverarbeitungTestenAzure Data FactoryPytorchInformatica PowercenterFlaskSnowflakeIT-ArchitekturDeep LearningDatenschichtenKanbanPandasMatplotlibAmazon RdsData LakePysparkScikit-learnKubernetesAWS GlueDaskPlotlyApache KafkaBetriebssystemeVerticaRestful ApisDockerDatabricksMicroservicesControl M
Hallo und vielen Dank für den Besuch meines Profils!
Ich bin Senior Data Engineer mit über 12 Jahren Erfahrung in der IT-Beratung. Ich habe mit Kunden wie E.ON, Carl Zeiss, Encavis, ING, KFW, WorldQuant, Catella und IQ Option an verschiedenen Projekten im Bereich Cloud Data Engineering, Datenmigration, Datenintegration, Data Lake sowie BI/DW gearbeitet. Einige wichtige Fakten über mich:
ETL-Werkzeuge:
Apache Airflow und Kafka, PySpark, AWS Glue, Databricks auf Azure, dbt, Informatica Powercenter, Microsoft Azure Data Factory, Denodo
Datenbanken
Snowflake, Redshift, Oracle 21c, Microsoft SQL-Server 2019, IBM DB2, Hadoop HDFS, PostgreSQL 10.7, MySQL, Amazon Aurora, MySQL
Big Data Ecosystem:
Vertica, Dask, Greenplum, ClickHouse, AWS Glue, Kinesis, Kafka, Hadoop 2.0, HDFS, Hive
Cloud-Technologien:
Amazon Web Services (AWS), Databricks, AWS S3, AWS RDS(PostgreSQL), Azure Blobs, Azure Batch Account, Azure Data Factory, Kubernetes, Docker
Reporting:
Power BI, Tableau, Shiny, Matplotlib, Plotly
Modellierung:
3-NF, Dimensional Modeling (Star & Snowflake schema), Data Vault (Raw Vault & Business Vault 2.0)
Software-Entwicklungsmethoden:
Agile, SCRUM, Waterfall
Programmiersprachen:
Python (zzgl. Flask, Pandas, PyTorch, Scikit-learn, PM4Py), R, PowerShell, JavaScript, Java, SQL, T-SQL, PL/SQL, UNIX/Bash Shell scripting
Data Mining:
Betriebsdaten Analyse, Selenium, pm4py
Maschinelles Lernen:
Deep Learning, Computer Vision, Natural Language Processing - NLP, Mathematical Modeling, Statistics
Modellierungswerkzeuge:
PowerDesinger
Anwendungsintegrationstools:
Informatica Intelligent Cloud Services (IICS) Data & Application Services,
Planungstools:
BMC Control-M 9.0.19, Automic UC4, Informatica Scheduler, Systemd Timers
Betriebssysteme:
Linux, AIX, Windows
Methoden/Techniken:
Hochverfügbarkeit, Real Application Cluster RAC, Stand-by, Failover Advanced Replication, Backup/Recovery), Continuous Integration, Kanban, Microservices, Test Automation, APIs, Projektmanagement, Qualitätsmanagement, A/B-Testing, Projektmanagement, Projektcontrolling
Ich bin Senior Data Engineer mit über 12 Jahren Erfahrung in der IT-Beratung. Ich habe mit Kunden wie E.ON, Carl Zeiss, Encavis, ING, KFW, WorldQuant, Catella und IQ Option an verschiedenen Projekten im Bereich Cloud Data Engineering, Datenmigration, Datenintegration, Data Lake sowie BI/DW gearbeitet. Einige wichtige Fakten über mich:
- Umfangreiche Erfahrung in der IT-Architektur, dem Design, der Entwicklung, Implementierung und dem Support von ETL- und ELT-Datenverarbeitungspipelines für Data Warehouses und Data Lakes. Ich nutze Tools wie Apache Airflow, Kafka, AWS Glue, Databricks auf Azure, Informatica Powercenter und Microsoft Azure Data Factory.
- Kompetenz in der Gestaltung und Anpassung von Datenmodellen mit Techniken wie dimensionaler Modellierung und Data Vault Modellierung.
- Erfahrung im Umgang mit strukturierten und halbstrukturierten Datenquellen, darunter Datenbanken, Parquet-Dateien in Hadoop, REST APIs, CSV, XML und JSON.
- Entwicklung verschiedener Datenschichten wie Stage Layer, Core Layer und Reporting Layer für eine effiziente und qualitativ hochwertige Datenverarbeitung.
- Enge Zusammenarbeit mit Datenarchitekten, Business Analysten, Produktmanagern und technischen Managern bei der Erstellung von Design, Architektur und Anforderungsspezifikationen für ETL/ELT-Pipelines.
- Umfassende Erfahrung in Scrum-Projekten mit aktiver Beteiligung an allen Phasen, wie Sprint-Planung und der Erstellung von User Stories und Tasks, usw.
ETL-Werkzeuge:
Apache Airflow und Kafka, PySpark, AWS Glue, Databricks auf Azure, dbt, Informatica Powercenter, Microsoft Azure Data Factory, Denodo
Datenbanken
Snowflake, Redshift, Oracle 21c, Microsoft SQL-Server 2019, IBM DB2, Hadoop HDFS, PostgreSQL 10.7, MySQL, Amazon Aurora, MySQL
Big Data Ecosystem:
Vertica, Dask, Greenplum, ClickHouse, AWS Glue, Kinesis, Kafka, Hadoop 2.0, HDFS, Hive
Cloud-Technologien:
Amazon Web Services (AWS), Databricks, AWS S3, AWS RDS(PostgreSQL), Azure Blobs, Azure Batch Account, Azure Data Factory, Kubernetes, Docker
Reporting:
Power BI, Tableau, Shiny, Matplotlib, Plotly
Modellierung:
3-NF, Dimensional Modeling (Star & Snowflake schema), Data Vault (Raw Vault & Business Vault 2.0)
Software-Entwicklungsmethoden:
Agile, SCRUM, Waterfall
Programmiersprachen:
Python (zzgl. Flask, Pandas, PyTorch, Scikit-learn, PM4Py), R, PowerShell, JavaScript, Java, SQL, T-SQL, PL/SQL, UNIX/Bash Shell scripting
Data Mining:
Betriebsdaten Analyse, Selenium, pm4py
Maschinelles Lernen:
Deep Learning, Computer Vision, Natural Language Processing - NLP, Mathematical Modeling, Statistics
Modellierungswerkzeuge:
PowerDesinger
Anwendungsintegrationstools:
Informatica Intelligent Cloud Services (IICS) Data & Application Services,
Planungstools:
BMC Control-M 9.0.19, Automic UC4, Informatica Scheduler, Systemd Timers
Betriebssysteme:
Linux, AIX, Windows
Methoden/Techniken:
Hochverfügbarkeit, Real Application Cluster RAC, Stand-by, Failover Advanced Replication, Backup/Recovery), Continuous Integration, Kanban, Microservices, Test Automation, APIs, Projektmanagement, Qualitätsmanagement, A/B-Testing, Projektmanagement, Projektcontrolling
Sprachen
DeutschMutterspracheEnglischverhandlungssicher
Projekthistorie
Projekt: Aufbau des Feature Store Platform für KI-gestürzte Apps. Mai 2025 – bis jetzt
Kunde: Allianz GI | Frankfurt am Main | Technologie für die Finanzindustrie
Rolle: Snowflake Data Architekt, Data Engineer
Projektdescription
Leitung der Konzeption und Implementierung von einer Databricks-basierten Forschungs- und Ausführungsplattform für Systematic Equity bei AllianzGI. Das Projekt konsolidierte Legacy-Systeme in einer einheitlichen Architektur, um das Daten-Onboarding zu optimieren, Leistung/Stabilität zu steigern und regulatorische Anforderungen (SDLC, Audit, Disaster Recovery) zu erfüllen. Die Plattform dient als „Golden Source“ für Investment-Signale, Reporting und Anwendungen und ermöglicht quantitativen Forschern und Portfoliomanagern, sich auf Strategie und Kundenbetreuung zu konzentrieren, durch Vereinfachung technischer Komplexität.
Aufgaben
Ergebnisse
Technologie-Stack
Projekt: Aufbau des Berichtswesens und DWH für Projektdaten. November 2024 – Juli 2025
Kunde: dm-drogerie markt | Karlsruhe | Drogeriehandel
Rolle: Snowflake Data Architekt, Data Engineer
Projektbeschreibung:
Das Hauptziel des Projekts war die Datenaufbereitung für Reporting und Analysen auf Basis der Planisware-Daten, insbesondere für MicroStrategy-Berichte. Hierzu wurden ein spezifisches Data Warehouse in Snowflake auf der Google Cloud Platform (GCP) für die Planisware-Projektdaten aufgebaut sowie Dimensionen und Fakten modelliert.
Aufgaben:
Projekt: Automatisierung der Datenverarbeitung für dynamische Preisgestaltung Januar 2024 – Oktober 2024
Kunde: E.ON | München/Essen | Energiesektor
Rolle: Snowflake Data Architekt
Ergebnisse:
Projekt: Aufbau des DWH und Reportingsysteme September 2023 – jetzt
Kunde: Carl Zeiss | Aalen | Feinmechanik und Optik
Rolle: Lead Data Engineer / Big Data Architekt
Technologie-Stack: Azure Cloud, Python, SQL Server/Azure Synapse Analytics, Azure Data Factory, Databricks, dbt , Azure OpenAI Tools: Azure DevOps, Confluence
Projekt: Aufbau des DWH und Reportingsysteme Mai 2023 – September 2023
Kunde: Encavis | Hamburg | Erneuerbare Energien
Rolle: Senior Data Engineer
Projekt: Aufbau des DWH und Reportingsysteme April 2022 – Mai 2023
Kunde: Catella (über age works services GmbH) | Berlin | Immobilien
Rolle: Senior Data Architekt / Business Intelligenz Spezialist
Projekt: Digitalisierung des Meldewesens Oktober 2021 – Dezember 2022
Kunde: ING-DiBa | Frankfurt am Main | Banking
Rolle: Senior Data Engineer / Business Intelligenz Spezialist
Projekt: Migration des DWHs für Meldewesen Oktober 2019 – Oktober 2021
Kunde: KFW (über Senacor) | Frankfurt am Main | Banking
Rolle: IT-Berater, Data Engineering und Business Intelligenz
Projekt: Aufbau von Big-Data-Pipelines für Tradingdaten April 2019 – Oktober 2019
Kunde: WorldQuant (über Luxoft) | Austin, United States | Technologie für die Finanzindustrie.
Rolle: Data Engineer / Data Scientist
Projekt: Datenanalyse für Marketing Team Feb 2018 - Oktober 2018
Kunde: IQ Option | Saint Petersburg | Technologie für die Finanzindustrie.
Rolle: Data Scientist
Projekt: Automatisierung von Dokumenten im Kunden- und Logistikmanagement Jul 2015 - Feb 2018
Kunde: Baltic Land | Saint Petersburg | Logistik
Rolle: System Analyst, Data Analyst
Notationen: Web service schemas (WSDL/XSD), Camunda BPMN, UML Tools: Archimate
Projekt: Cloud IT-Infrastruktur Aufbau Jul 2013 - Jul 2015
Kunde: Prometey | Saint Petersburg | Steuerberatung
Rolle: Systemingenieur
Das Projekt wurde ins Leben gerufen, nachdem ein Problem im Zusammenhang mit dem schnellen Wachstum des Unternehmens erkannt wurde: das Fehlen einer komfortablen und kostengünstigen Unternehmensinfrastruktur, die für die Arbeit mit umfangreichen Desktop-Anwendungen wie 1C Accounting, 1C Salary und Staff Management erforderlich ist. Daher wurde beschlossen, alle Daten von den lokalen Büro-PCs auf den Cloud-Server zu migrieren, wo die notwendige Infrastruktur wie ein Terminalserver für den Fernzugriff auf die gewünschten Anwendungen eingerichtet werden sollte. Im Rahmen dieses Projektes wurden Windows 2012 Server mit MS SQL-Server, Windows Terminal Server 1C Programme installiert, ein Raid 10 Disk Array erstellt und das inkrementelle Backup System konfiguriert.
Verantwortlichkeiten:
Kunde: Allianz GI | Frankfurt am Main | Technologie für die Finanzindustrie
Rolle: Snowflake Data Architekt, Data Engineer
Projektdescription
Leitung der Konzeption und Implementierung von einer Databricks-basierten Forschungs- und Ausführungsplattform für Systematic Equity bei AllianzGI. Das Projekt konsolidierte Legacy-Systeme in einer einheitlichen Architektur, um das Daten-Onboarding zu optimieren, Leistung/Stabilität zu steigern und regulatorische Anforderungen (SDLC, Audit, Disaster Recovery) zu erfüllen. Die Plattform dient als „Golden Source“ für Investment-Signale, Reporting und Anwendungen und ermöglicht quantitativen Forschern und Portfoliomanagern, sich auf Strategie und Kundenbetreuung zu konzentrieren, durch Vereinfachung technischer Komplexität.
Aufgaben
- Architektur eines bi-temporalen EAV-Feature-Stores (Entity-Attribute-Value), um Asset-Features (z. B. Umsatz, EBIT) mit Versionierung und Vintage-Daten zu erfassen, um Vorwärtsverzerrung im Backtesting zu vermeiden.
- Implementierung von Streaming-Pipelines auf Databricks Delta Lake zur Verarbeitung von 15+ TB Finanzdaten (45 Jahre Historie, tägliche Frequenz) mit inkrementellen Updates im ValueLog.
- Entwicklung der Projekt-Python-Bibliothek für Endnutzer (PMs/Forscher) zur Abfrage von Panels (Asset/Feature-Zeitreihen) und Integration in Investment-Workflows (z. B. Portfolioanalyse, Quality-Scoring).
- Umsetzung einer Medaillon-Architektur (Bronze/Silber/Gold-Schichten) für Datenerfassung, Transformation und Feature-Speicherung aus diversen Quellen (LSEG, Refinitiv, proprietäre Systeme).
- Aufbau eines Security Masters zur Vereinheitlichung von Asset-Mappings über Quellen hinweg und Sicherstellung der Datenintegrität.
- Mitwirkung an regulatorischer Compliance (Change Control, Umgebungstrennung) und Planung zukünftiger ML/AI-Integration.
Ergebnisse
- Beschleunigte Datenverarbeitung: Reduktion der Panel-Generierung von >1 Woche auf 1 Stunde (15+ TB-Datensätze), ermöglicht tägliche Vintage-Ansichten für historisches Backtesting.
- Vereinheitlichte kritische Prozesse: Konsolidierung von SQL Server, Data Factory und Legacy-Workflows in einer Plattform – reduzierter Wartungsaufwand und Freisetzung von Ressourcen für Wachstum.
- Strategische Entscheidungsgrundlagen: Etablierung einer „One-Stop-Shop“-Lösung für bereichsübergreifende Teams.
- Skalierbarkeit für Big Data: Grundlage für künftige AI/LLM-Integration, Alternative-Daten-Einbindung und unternehmensweite Kollaboration.
- Regulatorische Compliance: Umsetzung von SDLC-Prozessen, Zugriffskontrollen und Audit Trails via Databricks 2.0 (compliant-by-design).
Technologie-Stack
- Cloud: Azure, Databricks (Unity Catalog, Delta Lake, Streaming)
- Datenmodellierung: Bi-temporales EAV, Medaillon-Architektur
- Sprachen: Python, PySpark, SQL
- Tools: Azure Data Factory, Power BI (Visualisierung)
- Datenquellen: LSEG, Refinitiv, Worldscope, Data Access Layer (DAL)
- Konzepte: Feature Store, MLOps, Change Management
Projekt: Aufbau des Berichtswesens und DWH für Projektdaten. November 2024 – Juli 2025
Kunde: dm-drogerie markt | Karlsruhe | Drogeriehandel
Rolle: Snowflake Data Architekt, Data Engineer
Projektbeschreibung:
Das Hauptziel des Projekts war die Datenaufbereitung für Reporting und Analysen auf Basis der Planisware-Daten, insbesondere für MicroStrategy-Berichte. Hierzu wurden ein spezifisches Data Warehouse in Snowflake auf der Google Cloud Platform (GCP) für die Planisware-Projektdaten aufgebaut sowie Dimensionen und Fakten modelliert.
Aufgaben:
- Integration von Daten in das Data Warehouse und Zusammenarbeit im laufenden Projekt zur Einführung von Snowpark.
- Datenmodellierung in der 3. Normalform (3NF) und im Sternschema.
- Design, Implementierung und Betrieb von ETL/ELT-Prozessen unter Verwendung von Tools wie Denodo, Informatica, Matillion, Snowflake und Azure Data Factory.
- Mitarbeit bei der Weiterentwicklung und Modernisierung der Business-Intelligence-Landschaft in der Google Cloud Platform (Data Lake / Data Mesh).
- Zentrale Übersicht über Projektdaten: Durch die Datenaufbereitung und -modellierung wurde eine verbesserte Transparenz über die verschiedenen Projekte des Kunden erreicht.
- Optimierte Datenstrategie für Projektdaten: Standardisierung und Strukturierung der Daten für konsistentes Reporting, ergänzt durch virtuelle Datenebenen mit Denodo zur Reduktion von Redundanzen.
- Effiziente Datenintegration: Entwicklung einer Schnittstelle zu Planisware zur automatisierten Erfassung und Verarbeitung der Projektdaten.
- Verbesserte Berichts- und Analysemöglichkeiten: Bereitstellung aufbereiteter Daten für MicroStrategy-Berichte, um fundierte Entscheidungen auf Basis der Planisware-Daten treffen zu können.
- Skalierbare Architektur: Einsatz von Snowflake, Denodo und der Google Cloud Platform zur Sicherstellung einer flexiblen Erweiterbarkeit und eines effizienten Umgangs mit wachsenden Datenmengen.
- Reporting und Analyse: MicroStrategy-Berichte
- Data Warehouse: Snowflake, BigQuery
- Cloud-Plattform: Google Cloud Platform (GCP)
- Infrastructure as Code: Terraform
- Versionsverwaltung und CI/CD: GitLab
- Datenmodellierung: 3. Normalform (3NF), Sternschema (Dimensions- und Faktenmodellierung)
- Datenintegration: Entwicklung einer Schnittstelle zu Planisware
Projekt: Automatisierung der Datenverarbeitung für dynamische Preisgestaltung Januar 2024 – Oktober 2024
Kunde: E.ON | München/Essen | Energiesektor
Rolle: Snowflake Data Architekt
- Automatisierung der Datenverarbeitung für die dynamische Preisgestaltung hat die Fehlerquote, die früher durch die manuelle Datenaufbereitung verursacht wurde, erheblich verringert.
- Entwicklung des MVP für das dbt-Projekt mit anschließender Implementierung in die Produktionsumgebung der IT-Systeme des Kunden. Dies ermöglichte es, die Analyse der aktuellen Datentransformationen zu vereinfachen und die Suche nach Fehlern in der Geschäftslogik zu erleichtern.
- Die Implementierung der dbt ermöglichte auch ein besseres und detaillierteres Testen der resultierenden Daten.
- Entwicklung der automatisierten Generierung von Data Lineage, um Business Analysten ein besseres Verständnis des Prozesses und der Struktur der Abhängigkeiten in den Datenschichten zu ermöglichen.
Ergebnisse:
- Reduzierter Fehleranteil: Die Anzahl der fehlerhaften Daten in den Pipelines konnte um 15 % reduziert werden, was zu einer zuverlässigeren Datengrundlage für Preisanpassungsmodelle führt.
- Verkürzte Entwicklungszeit: Die Implementierung neuer Datenpipelines konnte um 50 % beschleunigt werden, wodurch sich das EVU schneller an veränderte Marktbedingungen anpassen kann.
- Modernisierte Datenarchitektur: Eine neue, skalierbare und performante Datenarchitektur wurde modelliert, die die Grundlage für die Entwicklung neuer intelligenter Preisanpassungssysteme bildet.
- Optimierte Datenpipelines: dbt wurde implementiert und die Pipelines optimiert, um eine effiziente und flexible Datenverarbeitung zu gewährleisten.
- Darstellung der Daten in Grafana
Projekt: Aufbau des DWH und Reportingsysteme September 2023 – jetzt
Kunde: Carl Zeiss | Aalen | Feinmechanik und Optik
Rolle: Lead Data Engineer / Big Data Architekt
- Dekomposition und Vereinfachung der Gesamtarchitektur des Databricks-Projekts, um sie sicherer, modularer und wartungsfreundlicher zu machen.
- Implementierung von Pipelines für den Empfang von Daten in verschiedenen Formaten (direkt über REST, als Dateien im Blob-Speicher, Mongo DB-Dokumente usw.)
- Hinzufügen neuer Transformationen der Daten in das spezifizierte Datenmodell gemäß einer definierten Geschäftslogik (Databricks, PySpark, Delta Tables, Azure Data Factory und natürlich SQL-Abfragen)
- Einrichtung eines Data Warehouse (Azure SQL und Time Series Mongo DB)
- Ermöglicht die Durchführung des ETL-Prozesses fast in Echtzeit; die Dateien werden sofort nach Erhalt oder in kleinen Stapeln alle x Sekunden verarbeitet: Pushen von Daten aus verschiedenen Quellen an Kafka ESB und deren Verarbeitung durch Delta Live Tables
- Entwickeln und Konfigurieren von Services und DWH-Systemen in der Azure Cloud-Umgebung
- Leitung eines Teams von Dateningenieuren: Planung und Priorisierung von Aufgaben, Teamimplementierung neuer Funktionen in die IT-Systeme des Kunden, Durchführung von Retro- und Tagesbesprechungen
- Entwicklung des MVP für das dbt-Projekt mit anschließender Implementierung in die Produktionsumgebung der IT-Systeme des Kunden. Dies ermöglichte es, die Analyse der aktuellen Datentransformationen zu vereinfachen und die Suche nach Fehlern in der Geschäftslogik zu erleichtern.
- Erstellung von Datensätzen auf der Grundlage der internen Dokumentation und des bestehenden Datenmodells, um Azure AI Search mit Daten zu füllen und eine intelligente Analyseplattform zu entwickeln (LLM + Azure KI Services)
- Skalierbarkeit: Das neue System ist in der Lage, die wachsenden Datenmengen effizient zu verarbeiten und zu analysieren. (Skalierbarkeit um 400 % gesteigert).
- Flexibilität: Die Cloud-native Architektur ermöglicht eine flexible Anpassung an sich ändernde Geschäftsanforderungen. (Vereinfachung der Integration neuer Datenquellen und Geschäftslogik).
- Performance: Die Datenverarbeitung erfolgt deutlich schneller und effizienter. (Verkürzung der Datenverarbeitungszeit um 80 %).
- Wartbarkeit: Der Code ist sauber, modular und gut dokumentiert, was die Wartung und Weiterentwicklung vereinfacht. (Reduktion der Ausfallzeiten auf unter 5 %).
Technologie-Stack: Azure Cloud, Python, SQL Server/Azure Synapse Analytics, Azure Data Factory, Databricks, dbt , Azure OpenAI Tools: Azure DevOps, Confluence
Projekt: Aufbau des DWH und Reportingsysteme Mai 2023 – September 2023
Kunde: Encavis | Hamburg | Erneuerbare Energien
Rolle: Senior Data Engineer
- Implementierung von Multithreading-Datenverarbeitung in Python und Prefect, was zu einer erheblichen Optimierung der Verarbeitung von Zeitreihendaten führte.
- Realisierung von Echtzeit-Datenpipelines mit Snowpipe von Snowflake
- Erstellung und Beschreibung eines Datenmodells und eines Datenspeichersystems mit DBT.
- Entwicklung von ETL-Pipelines für das Berichtswesen im Bereich Erneuerbare Energien (dbt + Prefect)
- Messung der Datenqualität mithilfe statistischer Methoden
- Erstellung und Unterstützung von Big-Data-Verarbeitungspipelines
- Entwickelte und Konfigurierte Dienste und DWH-Systeme in der Azure-Cloud-Umgebung mit Terraform
Projekt: Aufbau des DWH und Reportingsysteme April 2022 – Mai 2023
Kunde: Catella (über age works services GmbH) | Berlin | Immobilien
Rolle: Senior Data Architekt / Business Intelligenz Spezialist
- Entwicklung und Einführung eines Modells für maschinelles Lernen, das zur Vorhersage von Mieten mit einer Genauigkeit von über 91 % verwendet wurde.
- Erstellung eines Modells zur Optimierung der Vorhersage von Immobilienbewertungen anhand von Textbeschreibungen.
- Entwicklung in Python von ETL-Pipelines für Reporting (Dagster mit dbt)
- Entwicklung von Berichten, die GIS-Daten und -Strukturen verwenden, um operative Indikatoren auf einer Europakarte darzustellen
- Entwerfen von technischen Datenbankmodellen in Data Vault
- Automatisierung interner Prozesse: Einführung von automatisierten CI/CD, Python/SQL Testen in die Produktionsumgebung.
- Organisation der Migration von Daten von Azure (Microsoft SQL-Server) zum Snowflake
- Planen einer Architektur und Implementieren eines Testsystems für Fachanwender zur Einhaltung hoher Datenqualitätsstandards
Projekt: Digitalisierung des Meldewesens Oktober 2021 – Dezember 2022
Kunde: ING-DiBa | Frankfurt am Main | Banking
Rolle: Senior Data Engineer / Business Intelligenz Spezialist
- Entwicklung von ETL-Pipelines für Meldewesensysteme. Beschleunigung der gesamten täglichen Ladezeit um bis zu 40%
- Mitarbeit an Digitalisierungsprojekten der Bank (Spezifikation der Architektur von ETL-, Data Lake- und DWH-Systemen).
- Automatisierung interner Prozesse: Einführung von automatisierten CI/CD, Testen in die Produktionsumgebung.
- Vorbereitung von Spikes und Prototypen für die Migration älterer ETL-Lösungen in die Cloud-Infrastruktur
- Entwicklung von ETL-Prozessen für Anti-Financial Crime (AFC) Berichte.
Projekt: Migration des DWHs für Meldewesen Oktober 2019 – Oktober 2021
Kunde: KFW (über Senacor) | Frankfurt am Main | Banking
Rolle: IT-Berater, Data Engineering und Business Intelligenz
- Implementierung von komplexen Datenintegrationsprozessen auf Basis moderner ETL-Frameworks in Informatica;
- Entwerfen von technischen Datenbankmodellen auf der Basis verschiedener Modellierungsparadigmen (3NF, Data Vault, Star, ...);
- Co-Design von kundenspezifischen Frameworks innerhalb der eingesetzten ETL-Tools;
- Automatisierung von Datenqualitätstests für ETL-Pipelines (PL/SQL, Bash, Jenkins).
- Entwicklung von ETL-Prozessen für Anti-Financial Crime (AFC) Berichte.
Projekt: Aufbau von Big-Data-Pipelines für Tradingdaten April 2019 – Oktober 2019
Kunde: WorldQuant (über Luxoft) | Austin, United States | Technologie für die Finanzindustrie.
Rolle: Data Engineer / Data Scientist
- Zeitreihenanalyse, Gruppierung, Anomalieerkennung, Dimensionalitätsreduktion
- Datenanalyse von Big Data im Finanzhandel. Verwaltung von mehr als 3 TB an Datensätzen mit Zeitreihen.
- Das ETL-Szenario wurde umgeschrieben, um es von 11 Verarbeitungsstunden auf 45 Minuten zu beschleunigen.
- Verhinderung von Geldverlusten durch das entwickelte Alarmsystem für die Qualität der Handelsdaten
- Standardisierung des Beitrags von ETL-Skripten zur aktuellen Datenpipeline unter Verwendung von BPMN und DFD (Datenflussdiagramm)
Projekt: Datenanalyse für Marketing Team Feb 2018 - Oktober 2018
Kunde: IQ Option | Saint Petersburg | Technologie für die Finanzindustrie.
Rolle: Data Scientist
- Entwicklung von Modellen zur Vorhersage der profitabelsten Kundengruppen mit Hilfe von Random Forest Classifier (Vorhersage von Marketing Qualified Leads)
- Modellierung und Prognose von Kundenzahlungsströmen.
- Erstellen eines Mikrodienstes zur Bereitstellung regelmäßiger Datensätze für einen ständig selbstlernenden NLP-Algorithmus für maschinelles Lernen, der einen intelligenten Nachrichten-Feed bereitstellt.
- Etablierung von Standards für die Dokumentation von Data-Science-Modellen
- Entwicklung von Marketingberichten in Shiny und Tableau für die tägliche Nutzung und ETL-Prozesse unter Verwendung von Google Analytics API
Projekt: Automatisierung von Dokumenten im Kunden- und Logistikmanagement Jul 2015 - Feb 2018
Kunde: Baltic Land | Saint Petersburg | Logistik
Rolle: System Analyst, Data Analyst
- Analyse und Automatisierung von internen Geschäftsprozessen mit Camunda BPM
- Integrierung und leitende Entwicklung einer internen Android-Anwendung zur Digitalisierung von Geschäftsprozessen
- Entwicklung der persönlichen Kontoanwendung für Firmenkunden.
- Datenanalyse im Bereich Internet-Marketing mit Integration verschiedener Dashboards in das Unternehmens-CRM
- Sorge für die Pflege und Optimierung der Unternehmenswebsite: Entwicklung und Anpassung von Plugins für das Drupal Content-Management-System (CMS).
- Leitung der Entwicklung des internen Marketing-Tools: Überprüfung der Abnahmetestspezifikationen und gelegentliche Durchführung von Abnahmetests der entwickelten Funktionalität, Erstellung der Spezifikations
- Vorbereiten von Finanzberichten für die Unternehmensleitung
- Entwicklung von ETL-Pipelines in SQL-Server Integration Services
Notationen: Web service schemas (WSDL/XSD), Camunda BPMN, UML Tools: Archimate
Projekt: Cloud IT-Infrastruktur Aufbau Jul 2013 - Jul 2015
Kunde: Prometey | Saint Petersburg | Steuerberatung
Rolle: Systemingenieur
Das Projekt wurde ins Leben gerufen, nachdem ein Problem im Zusammenhang mit dem schnellen Wachstum des Unternehmens erkannt wurde: das Fehlen einer komfortablen und kostengünstigen Unternehmensinfrastruktur, die für die Arbeit mit umfangreichen Desktop-Anwendungen wie 1C Accounting, 1C Salary und Staff Management erforderlich ist. Daher wurde beschlossen, alle Daten von den lokalen Büro-PCs auf den Cloud-Server zu migrieren, wo die notwendige Infrastruktur wie ein Terminalserver für den Fernzugriff auf die gewünschten Anwendungen eingerichtet werden sollte. Im Rahmen dieses Projektes wurden Windows 2012 Server mit MS SQL-Server, Windows Terminal Server 1C Programme installiert, ein Raid 10 Disk Array erstellt und das inkrementelle Backup System konfiguriert.
Verantwortlichkeiten:
- Betrieb von Windows Server 2012 (Terminal Server 1C), Ubuntu Server 12.04 (Web Services Firma, XMPP Chat für Mitarbeiter, VPN für Remote Desktop Access)"
- Anpassung des Cloud-Systems EDI (OwnCloud / Nextcloud + Onlyoffice Dokumentenserver)
- Betreuung und Weiterentwicklung der Firmenwebsite: Entwicklung und Anpassung der Plugins für das Wordpress CMS (Content-Management-Systemen)
- Entwicklung einer Software zur Automatisierung der Erstellung von physischen Mailings
- Pflege von Backups und Reservierungen
Portfolio
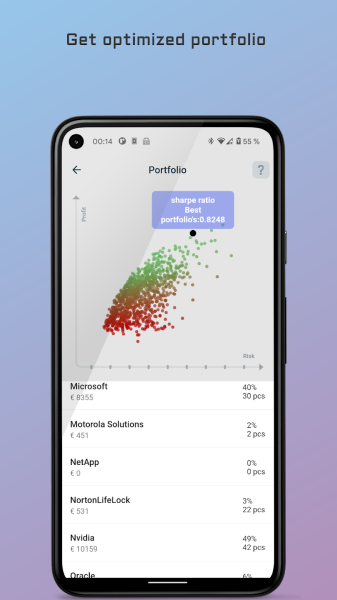
MPT Algorithm Python
Python Modern Portfolio Algorithm für eine Mobile-Anwendung
Bewertungen

exali Berufshaftpflicht-Siegel
Das original exali Berufshaftpflicht-Siegel bestätigt dem Auftraggeber, dass die betreffende Person oder Firma eine aktuell gültige branchenspezifische Berufs- bzw. Betriebshaftpflichtversicherung abgeschlossen hat.
Versichert bis: 01.01.2027